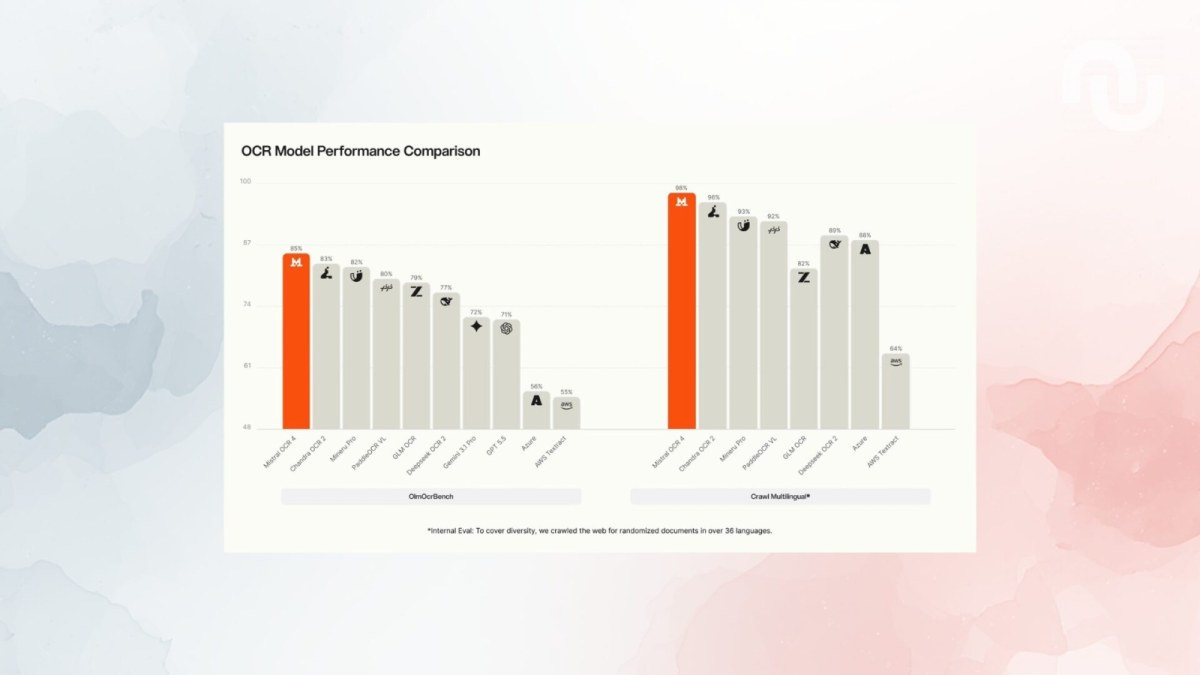
170 langues, des écritures médiévales illisibles, des archives administratives empilées depuis des décennies : Mistral vient de poser sur la table un outil qui ressemble moins à un gadget qu’à une solution à un problème bien réel. OCR 4, la nouvelle version de son moteur de reconnaissance de documents, franchit un cap que peu d’acteurs ont osé viser.
La reconnaissance optique de caractères, ce n’est pas nouveau. Mais jusqu’ici, ces outils butaient systématiquement sur deux murs : les écritures manuscrites anciennes et les langues rares ou à faible représentation numérique. Mistral affirme avoir fait reculer ces deux obstacles simultanément. L’enjeu dépasse largement le confort des développeurs qui l’intègreront via API.
Pensez aux archives notariales, aux registres paroissiaux, aux fonds diplomatiques conservés dans des cartons depuis deux siècles. La numérisation de ces documents existe, mais leur indexation et leur lecture automatique restaient hors de portée. OCR 4 cible directement ce gisement colossal, y compris côté administrations publiques qui croulent sous des montagnes de papier non exploitable.
« Derrière l’outil pour développeurs, l’enjeu est très concret : numériser des montagnes d’archives, jusque dans nos administrations. »
Ce qui est remarquable ici, c’est la direction choisie par la pépite française de l’IA. Pendant que ses concurrents américains s’acharnent sur les assistants conversationnels grand public et l’intégration dans les outils de bureau, Mistral cible une infrastructure critique : la mémoire écrite de l’humanité. C’est moins spectaculaire à démontrer dans une démo, mais potentiellement bien plus structurant à long terme.
Reste à savoir si les institutions culturelles et gouvernementales, réputées pour leur prudence face aux outils externes, sauteront le pas. La technologie est là. La volonté administrative, elle, est une autre affaire.
En savoir plus sur Glorieux Geek
Subscribe to get the latest posts sent to your email.









